Menu principal
Vous êtes ici
L'archive web locale du pauvre, sans prise de tête

💡 Pour une meilleure appréhension, il est recommandé de lire ce tutoriel sur le wiki ou à l'aide du mode lecture de votre navigateur web.
En attendant un web majoritairement décentralisé via IPFS (ou une autre technologie) archiver le web reste une pratique utile pour diverses raisons, par exemple :
- comme contre mesure à la censure
- pour consulter des pages web hors ligne
- en cas d'indisponibilité ou inaccessibilité temporaire
- ou pour avoir un historique lorsqu'un site ou une page web disparaît (ou est remplacé⋅e par une autre ou encore est modifié⋅e mais qu'il manque des informations)
Si l'acteur principal dans ce domaine - Internet Archive avec son archive.org - fait un travail remarquable, reste que tout n'est pas toujours archivé ou archivable et que vous pouvez vous retrouver déconnecté d'internet ou avoir une faible bande passante, insuffisante pour consulter ce dont vous avez besoin.
De plus si certains sites comme Wikipédia possèdent bien une version téléchargeable, le moins que l'on puisse dire, c'est que c'est loin d'être une généralité.
D’où l'idée d'avoir sa propre archive web. Même si elle restera probablement modeste, si de nombreuses personnes en ont, un historique du web décent pourrait advenir.
Comme vous allez le constater, il n'est pas nécessaire d'avoir un équipement coûteux ou complexe, l'objectif ici est simplement de sauvegarder tout le contenu d'une page web dans un seul fichier avec à côté les contenus audio ou vidéo qu'elle pourrait contenir.
Un disque dur de taille suffisante (à vous de choisir en fonction de vos besoins) et les logiciels suivants seront nécessaires.
Prérequis techniques
- L'extension SingleFile pour Mozilla Firefox
- incron pour déclencher le script
- bash pour le script principal
- awk pour traiter une chaîne de caractères
- youtube-dl pour la sauvegarde des médias (vidéos, podcasts)
optionnel :
Installation
Incron, youtube-dl, archivement
Selon votre distribution :
sudo dnf install incron youtube-dl archivemount
ou
sudo dnf install incron youtube-dl archivemount
les bash, awk, tar sont généralement déjà installés (ou vous les utilisez déjà pour d'autres choses)
Configuration
SingleFile
1.
Clic droit sur l'icône de l'extension puis menu Gérer l'extension
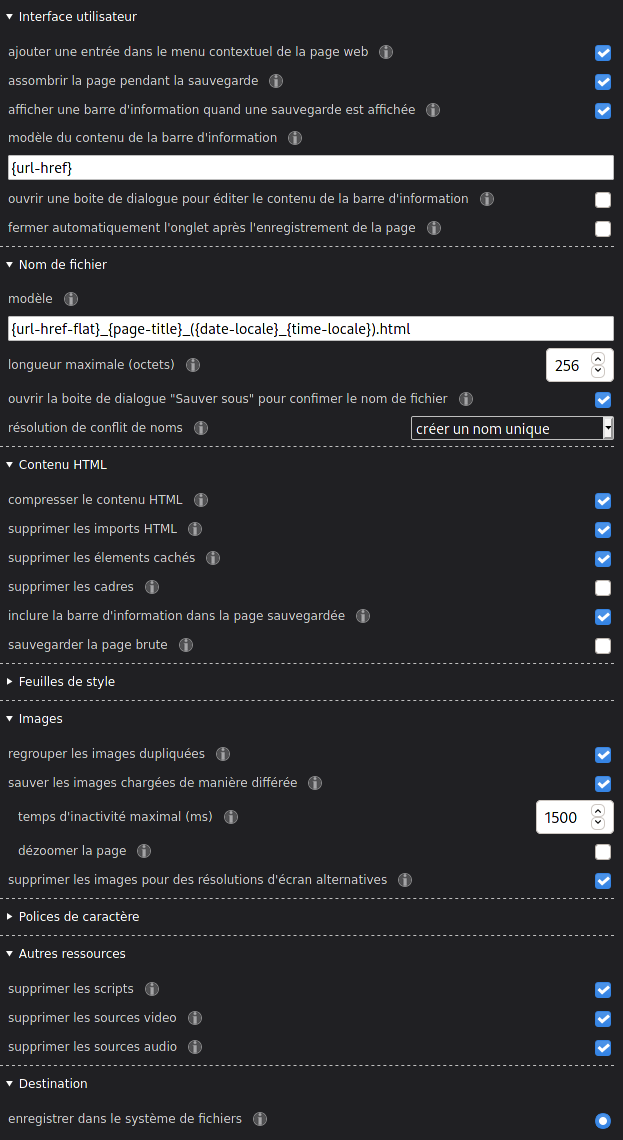
Onglet "Préférences"
Ne pas oublier d'ajouter l'URL de la page sauvegardée dans la barre d'information
{url-href}
... et d'inclure la barre d'information dans la page sauvegardée.
Je propose également le modèle de nom de fichier (nomenclature) suivante :
{url-href-flat}_{page-title}_({date-locale}_{time-locale}).html
Ne pas hésiter à choisir des noms de fihiers longs.

2.
Avec les options suivantes :
Incron
sudo rm -f /etc/incron.allow
echo $USER | sudo tee -a /etc/incron.allow
incrontab -e # équivalent de crontab -e, permet de surveiller un dossier et de déclencher un script en fonction des événèments
Ajouter la ligne suivante :
/chemin/de/l/archive IN_CLOSE_WRITE /chemin/de/l/archive/incron-script-archive-web.sh
# cette ligne va permettre à incron de :
# 1. Surveiller le dossier : ...
# 2. Et lorsqu'un fichier est créé ou modifier
# 3. Lancer le script : ...
Sauvegarder.
Automatisation
Lors de l'enregistrement de la page web, un dossier est créé avec le nom du site. La page déplacée à l'interieur de ce dossier et youtube-dl tente de télécharger les podcasts ou la vidéo qui se trouvent sur la même page.
nano /chemin/de/l/archive/incron-script-archive-web.sh
# le script contiendra :
FULLPATH="$1"
FILENAME="$2"
if [[ $FILENAME == **.html ]] # Si le fichier créé ou modifié est au format HTML
then
URL=$(grep -m 1 "url:" "$FULLPATH/$FILENAME") # Récupère l'URL exacte de la page sauvegardée dans les métadonnées enregistrées par l'extension SingleFile
URL=$(echo ${URL//url:/}) # Supprime la partie qui commence par "url :"
DOMAIN=$(echo $URL | awk -F/ '{print $3}') # Extraction du nom de domaine
cd "$FULLPATH" # Se rendre dans le dossier de l'archive
mkdir "$DOMAIN" # Création d'un dossier au nom du site
mv "$FILENAME" "$DOMAIN" # Déplacement de la page dans ce dossier
cd "$DOMAIN/"
youtube-dl -o '$FILENAME_%(title)s-%(id)s.%(ext)s' "$URL" # Sauvegarde des médias de cette page
else
echo "Fichier non HTML"
fi
Réduction de l'espace disque occupé par l'archive
Étant donné que les fichiers HTML seront en grand partie constitués de texte, le gain potentiel - même avec une compression sans perte - devrait être assez important.
sudo dnf install archivemount
touch fichier.vide
tar -czvf archive.tar.gz fichier.vide # Création du fichier d'archive
# Ajouter en début de script :
archivemount /chemin/de/archive.tar.gz /chemin/de/l/archive/ # montage du fichier d'archive
Lorsque l'archivage des fichiers est terminé :
# Ajouter en fin de script :
umount /chemin/de/l/archive/
- Blog de Laurent Espitallier
- Connectez-vous ou inscrivez-vous pour publier un commentaire


